

Purpose-built for GPU infrastructure.
All the way down.
Root-cause analysis and remediation across device, fabric, and storage.
Caladrius finds the cause across device, fabric, and storage, and drives the fix.
When a GPU job stalls or slows, Caladrius names which layer owns it: the model, the GPU, the fabric, or the storage. Your engineers stop guessing across domains.
Dead ranks, NCCL binding faults, fail-slow stragglers, scheduler preemptions, KV-cache pressure. Caladrius names the actual cause across GPU failure modes, not another wall of alerts.
Caladrius doesn't stop at the diagnosis. It drives the fix under your approval, verifies it held, and rolls back if it didn't.
GPU infrastructure isn't a black box to Caladrius. It reads the device, fabric, and storage signals general tools skip, next to the tools you already run.
Built for your GPU stack. Whoever runs it.
For neocloud operators: attribute and remediate faults across your whole fleet. Less time proving fault, lower cost to serve, and a clear answer for your customers too.
For enterprise AI/ML teams: find the root cause across your own GPU fleet, from the model down to the silicon.
One platform for GPU-infrastructure performance and reliability
See, understand, and resolve issues across the GPU stack, devices, fabric, and storage, in one place.
Root cause across the GPU stack
From a red training job to a degraded storage node or a flapping InfiniBand link, Caladrius traces the failure chain across GPU (XID, ECC, thermal), NVLink, fabric, and storage. Know in seconds whether it's the model, the GPU, the network, or the disk.
See the platform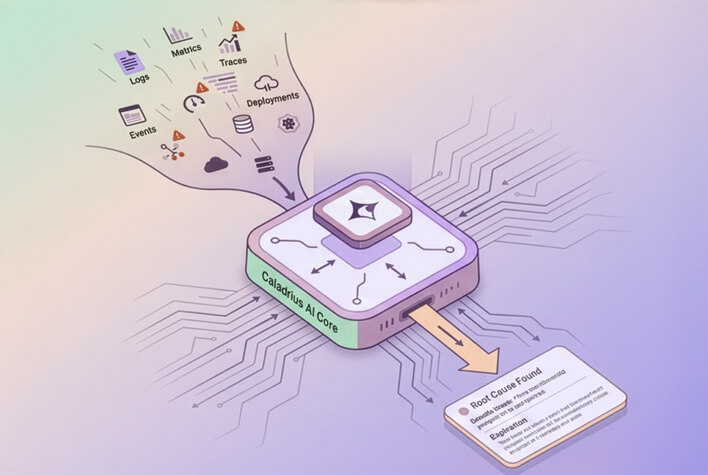

Your whole fleet, from GPU to data center
An always-on view of every tenant, rack, node, and GPU, plus the fabric and storage behind them. Utilization, goodput, XID errors, NVLink and InfiniBand health, and storage latency, in real time.
See the platformOne root cause, not a thousand alerts.
A single bad GPU or flaky link can fire thousands of redundant XID and DCGM alerts. Caladrius collapses the storm into the one fault that matters and the action to take.
See the platform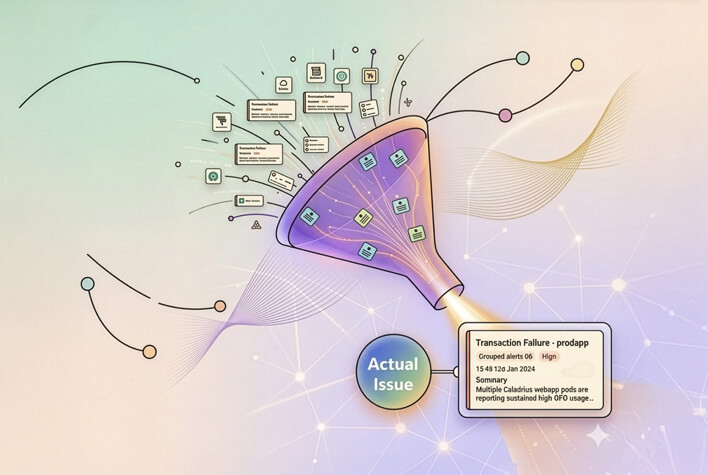









Supported Integrations
Caladrius connects with your existing tools and platforms to provide comprehensive observability across your entire stack.








Security and control
How Caladrius runs under your control.Caladrius acts only within the permissions you set, and you decide what it may recommend and what it may execute.
Every action Caladrius proposes or takes is logged and attributable.
Scoped views enforce that each customer sees only their own resources.