
The root cause, found.
The fix, driven and verified.
Root-cause analysis and remediation for GPU infrastructure. Caladrius finds the cause across failure modes and drives the fix to a verified result, on your approval.
- The actual root cause across failure modes, not another wall of alerts
- Which layer it lives in: the model, the GPU, the fabric, or the storage
- The fix driven, then verified against the result
- On any GPU you run, owned or rented
When a training or inference job stalls or slows, the cause can lie anywhere from the GPU devices to the fabric to storage and checkpoints to the workload itself, and finding it means engineers correlating signals by hand. Caladrius reaches into the suspect cluster and finds it, attributes it to the layer responsible, and closes the loop on the fix.
From a stalled job to
a confirmed fix.
Diagnose the fault, attribute it to the right layer, drive the fix on your approval, and verify it held.
Diagnose the fault,
not the symptom
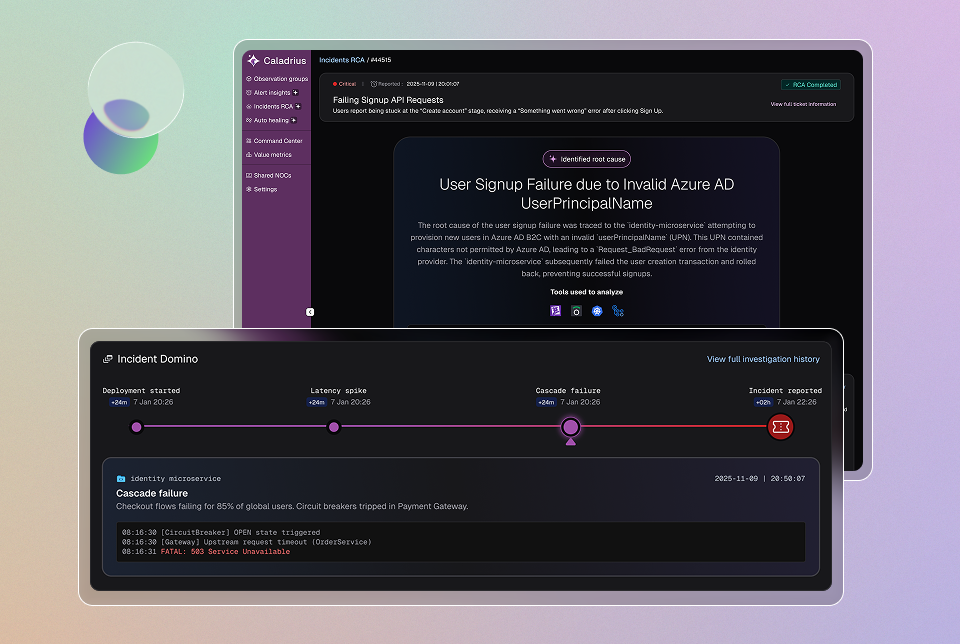
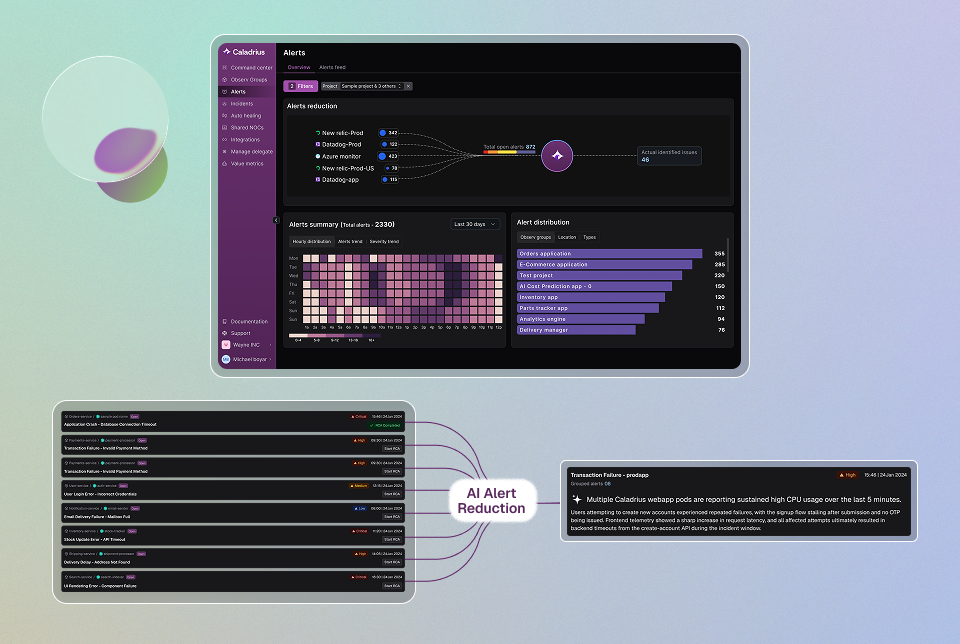
Caladrius correlates the device, fabric, storage, and workload signals into a single incident and identifies the fault behind it, across failure modes.
How it works
- Correlates device, fabric, storage, and workload signals into one incident
- Reads the GPU-domain signals general tools skip: XID and ECC errors, thermals, NVLink and InfiniBand health, goodput, storage latency
- Identifies what actually went wrong across failure modes: dead ranks, NCCL binding faults, fail-slow stragglers, scheduler preemptions, KV-cache pressure, ECC-driven drain
- Traces the failure chain from the red job back to the node, link, or disk behind it
What this means
- Less time hand-correlating across device, fabric, and workload
- A starting point that is the problem, not the noise around it
- One thing to act on, even as one bad GPU fires a thousand alerts
A diagnosis solid enough to act on.
Attribute it to
the layer that owns it
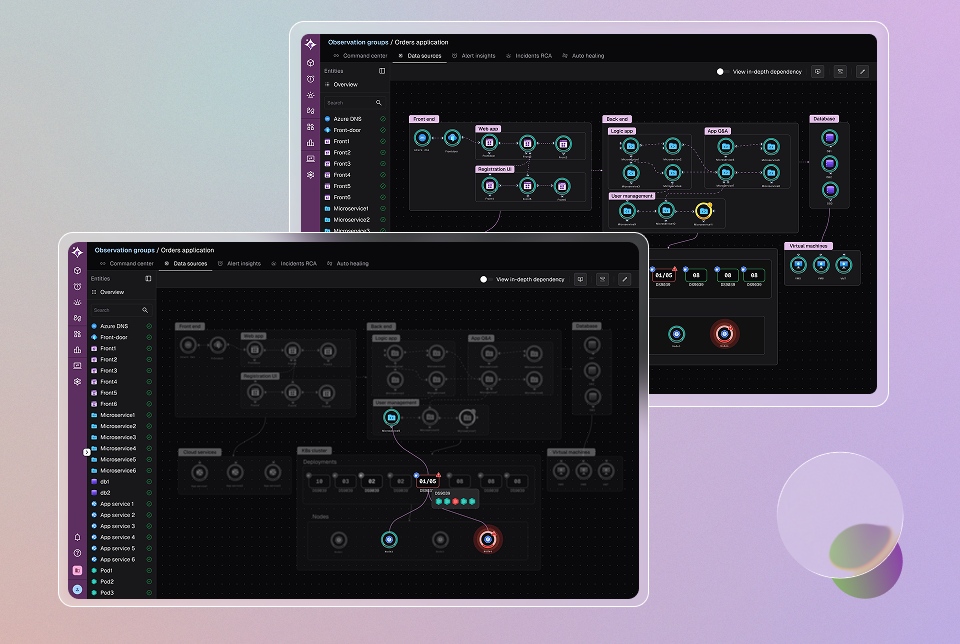
A symptom shows up in the job, but the cause can live a layer down. Or three. Caladrius places each one on the layer it comes from, the model, the GPU, the fabric, or the storage, so the work goes to the right place the first time.
How it works
- Separates a model or workload issue from a GPU, fabric, or storage issue, and shows you which domain to work
- Carries the evidence for the call, so the attribution is reviewable, not merely asserted
When you run a fleet for others, internal teams or external customers
- The same attribution says which side of the boundary a problem is on. When it is on their side, it gets handed off quickly, with the evidence, so no one wastes time or goodwill on assigning blame
- When it is on your side, it routes straight into the fix loop
Attribution puts the work on the right layer before the fix begins.
Fix it,
and prove it held
Most tools stop at the diagnosis and hand you the work. Caladrius proposes the fix for what it found, runs it once you approve, and checks the result before it calls the incident closed.
How it works
- Proposes the fix for what was diagnosed: drain a dead rank, rebind NCCL, right-size the KV-cache, requeue around a failed node
- Runs only what you approve, and only within the permissions you grant
- Checks the result against service-level indicators, and reverts the change if the result is worse
What this means
- Action on the problem, not one more recommendation to work through
- Evidence the fix worked, not just that the change went out
- A safe default: a change that does not hold is undone on its own
The loop closes with proof the problem is gone.

Works with your stack, under your control
Caladrius works alongside the tools you already run, and you decide what it can do.
Caladrius works within the permissions you set. You decide what it may recommend and what it may execute, and it acts only on what you approve.
Every action Caladrius proposes or takes is logged and attributable, so you can audit what happened and why.
Scoped views mean each tenant sees only its own resources.
How it helps you
Less time spent settling which side a problem is on, fewer SLA credits paid to end disputes, and happier customers who got a fix instead of an argument.
A fast answer on whether a GPU stack issue is yours to fix or your provider's, instead of hours lost to a problem that turns out to sit below your application.
One way to find and fix problems across every GPU you run, owned or rented, so your platform team learns one tool, not one per environment.